

본 내용은 크롤링 봇 만들기와 연관됩니다.
https://js990317.tistory.com/11
AWS Lambda 활용해서 크롤링 봇 만들어보기
AWS 람다란? 서버를 프로비저닝하거나 관리하지 않고도 코드를 실행할 수 있게 해주는 컴퓨팅 서비스입니다. Lambda는 고가용성 컴퓨팅 인프라에서 코드를 실행하고 서버와 운영 체제 유지 관리,
js990317.tistory.com
만약 람다 함수가 많이 존재하고 겹치는 라이브러리들이 많으면 어떻게 할까?
이때 람다의 layer을 사용하면 중복되는 라이브러리를 일일이 올리지 않아도 계층으로 꺼내와서 사용할 수 있습니다.
이를 실습으로 포스팅 해보겠습니다.
먼저, 저번에 웹 크롤링을 사용하기 위해 bs4 라이브러리를 사용한것을 토대로 진행해보겠습니다.
먼저, layer 즉, 계층을 하나 만들어줘야하는데 람다 메뉴에 보면 계층이라는 탭이 있습니다.
이를 통해 계층 생성을 진행해주면 되는데,
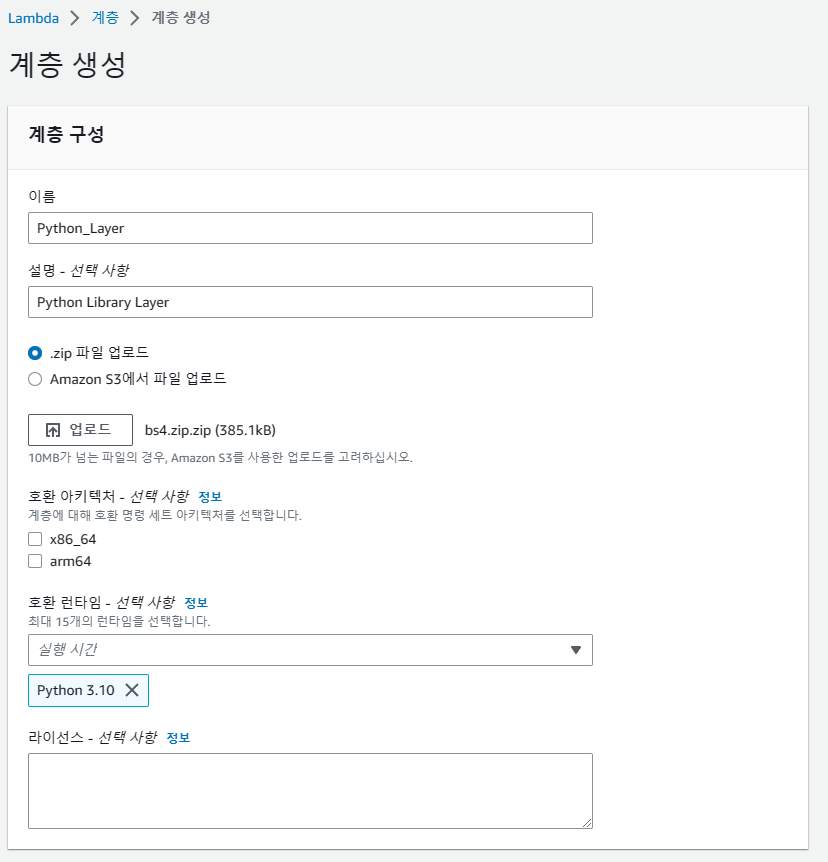
이름은 Python_Layer과 설명은 파이썬 라이브러리 계층으로 써놓은뒤 cmd로 다운로드 받아놨던, bs4 압축파일을 업로드하여 계층을 새로 생성해줬습니다.
이때 주의할점은, 실제로 라이브러리가 한꺼번에 사용될 수 있기 때문에 python이라는 폴더 안에 모든 라이브러리가 담겨있음과 동시에 압축파일의 python 폴더가 최상위 계층에 있어야 정상적으로 Layer가 작동한다.
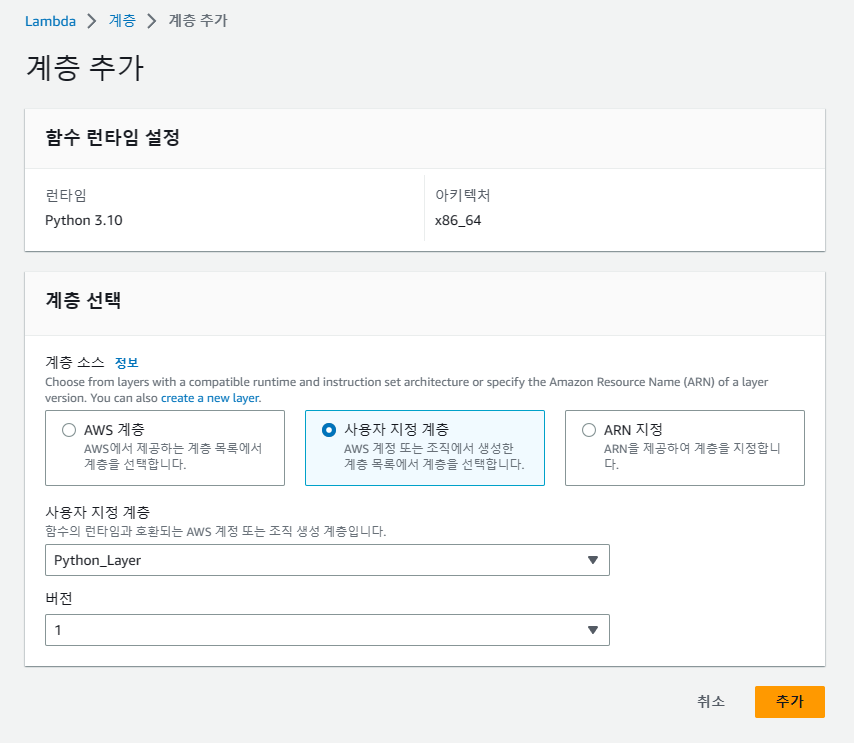
이제 기존에 생성해놓은 람다 함수로 돌아가 계층 추가를 해주면 되는데, 사용자 지정 계층에서 방금 만든 계층과 버전을 선택해준뒤, 추가해줍니다.
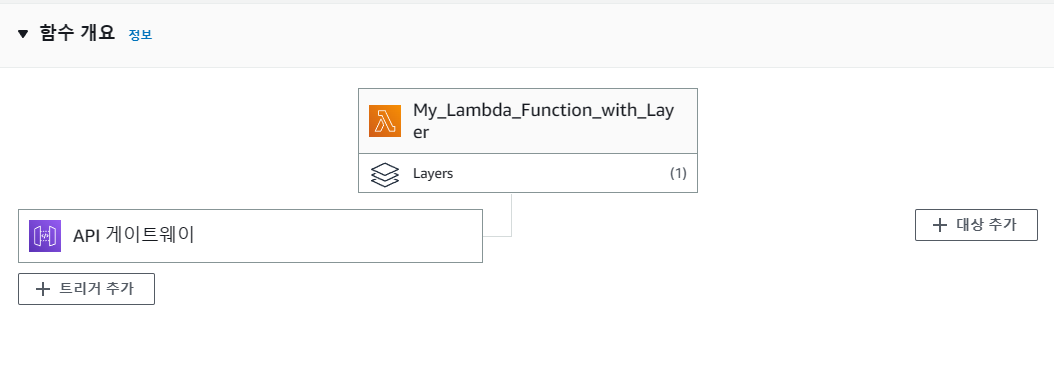
정상적으로 Layer가 추가되었고 똑같이 람다 함수 코드에 코드를 추가해준뒤,
import json
import urllib.request
from bs4 import BeautifulSoup
def lambda_handler(event, context):
url = "http://www.google.com"
soup = BeautifulSoup(urllib.request.urlopen(url).read(), "html.parser")
a_tags = soup.find_all('a')
result_list = []
for i in a_tags:
result_list.append(i.get_text())
return {
'statusCode:200,'
'body': json.dumps(result_list)
}게이트웨이 엔드포인트를 따라 들어가면 구글의 링크들을 파싱해온것을 볼 수 있습니다.
많은 람다함수들이 존재하지만, 그중에서 겹치는 라이브러리들이 있다면 계층을 유용하게 활용해볼 수 있을 것 같습니다.
본 실습은 동빈나님의 영상을 참고하였습니다.
'Cloud' 카테고리의 다른 글
| Aws EC2에서 Filezilla 연결하기 (0) | 2023.05.04 |
|---|---|
| aws ec2 환경에서 Chrome,ChromeDriver,Selenium 설치하는법 (0) | 2023.05.04 |
| AWS Lambda로 게시판 서버 API 만들어보기 ① (0) | 2023.04.26 |
| AWS Lambda 활용해서 크롤링 봇 만들어보기 (0) | 2023.04.25 |
| [AWS] EC2 인스턴스로 끄투 서버 구축해보기 (0) | 2023.04.21 |